
 Автор статьи:
Автор статьи:
“Яндекс Wordstat” — это бесплатный сервис просмотра статистики поисковых запросов. В самом “Яндексе” он называется "Подбор слов", но в рунете прочно закрепилось название Wordstat (“Вордстат”), по имени поддомена, на котором он расположен — wordstat.yandex.ru.
В статье мы подробно расскажем, зачем и как его можно использовать, о нюансах подбора ключевых слов, а также о полезных дополнениях к “Вордстату”.
Содержание статьи:
- Зачем нужен Wordstat?
- Ограничения сервиса
- Основной интерфейс и просмотр статистики в режиме "По словам"
- Какие запросы “Вордстат” включает и не включает в выборку?
- Как уточнить запрос с помощью операторов
- Примеры сложных запросов с использованием операторов
- Просмотр статистики в режиме "По регионам"
- Просмотр статистики в режиме "История запросов"
- Полезные программные расширения
- Заключение
Зачем нужен “Вордстат”?
Wordstat показывает статистику поисковых запросов в “Яндексе” в разрезе регионов, устройств и периодов. С его помощью можно:
- проверить популярность того или иного запроса в целом или в конкретном регионе, его сезонность;
- подобрать ключевые слова для рекламы в “Яндекс.Директ”;
- собрать семантическое ядро для продвижения сайта; “Вордстат” для этого не самый удобный инструмент, но если у вас небольшой сайт — это возможно;
- узнать, что ищут ваши потенциальные клиенты, как можно расширить ассортимент;
- найти идеи для контента (статей, постов в соцсетях).
Ограничения сервиса
Недостатки Wordstat связаны как с его функциональностью в целом, так и с неудобствами использования его веб-интерфейса. Последний не менялся больше 20 лет. Поэтому было создано множество сторонних приложений, которые выбирают статистику из “Вордстата”, обращаясь к нему по API, и представляют ее в более удобном виде.
Основные недостатки:
- Для использования нужно логиниться в ваш аккаунт в “Яндексе”.
- Часто сервис требует перед обработкой каждого ключевого слова вводить капчу, что очень неудобно. Капча может запрашиваться, например, если вы находитесь за границей, с вашего IP поступает слишком много запросов, ваш браузер не хранит куки или вы используете Adblock.
- Нет массовой загрузки фраз. Нужно вводить ключевые слова по одному. Однако, используя операторы, можно получить результаты сразу по нескольким запросам. Об этом мы расскажем ниже.
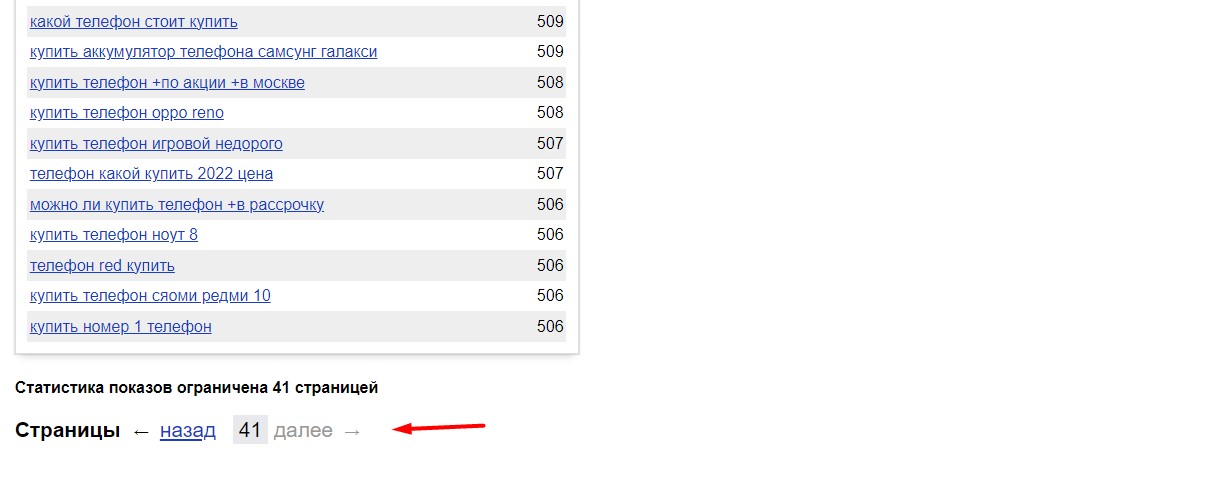
- Количество результатов ограничено: не более 2050 за раз. При этом результат разбит на страницы, по 50 ключевиков на одной. Максимальное число страниц — 41.
- Из веб-интерфейса “Вордстата” нельзя массово выгрузить все запросы — приходится их копировать по одному или выделять и копировать все и потом очищать от лишних символов. Этот недостаток решают различные расширения, о которых мы расскажем ниже.
- Статистика “Вордстата” неполная. В нее не попадают многие низкочастотные запросы. Также нужно учитывать, что многие ищут информацию не в “Яндексе”, а в других поисковиках. Последнее особенно актуально для анализа поиска с телефонов и планшетов, так как на “Андроиде”, например, предустановлен Google-поиск, и не все его меняют.
- В статистике Wordstat встречаются "искусственные" запросы, которые создаются ботами для накрутки поведенческих факторов. Впрочем, такие могут быть и в статистике других поисковых систем.
Почему же многие пользуются “Подбором слов”, несмотря на все недостатки инструмента?
Причин, на наш взгляд, две:
- Простота и доступность. Не нужно скачивать и устанавливать никаких приложений, регистрироваться в новых сервисах. “Вордстат” доступен в любом браузере, а аккаунт “Яндекса” есть практически у каждого.
- Бесплатность. Сторонние приложения, обеспечивающие доступ к Wordstat по API, часто платные. Кроме того, в них все равно остаются и даже усугубляются некоторые проблемы “Вордстата”. Например, из-за частых обращений к API приходится регистрировать новые аккаунты “Яндекса”, покупать антикапчу и т. д.
Основной интерфейс и просмотр статистики в режиме "По словам"
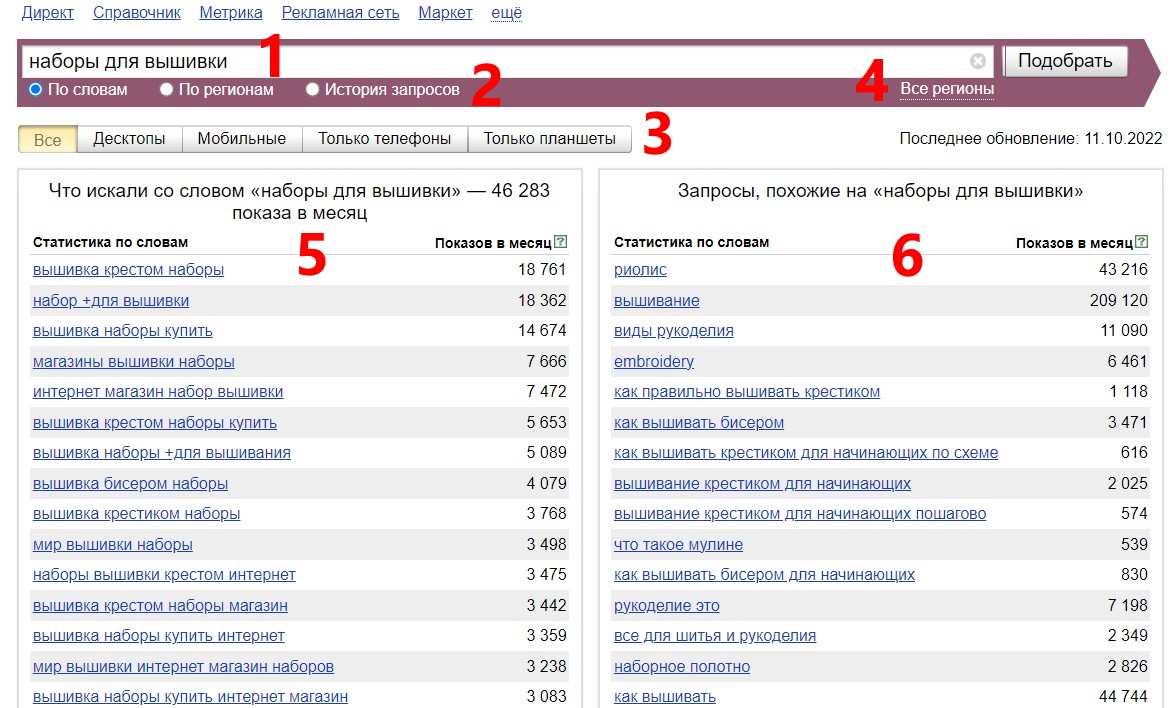
Основной интерфейс, который не меняется при разных режимах использования, состоит из:
- Строки поиска. Сюда вы вводите запрос.
- Панели выбора режимов просмотра статистики: по словам, по регионам, история запросов. В зависимости от выбранного режима будет меняться сама выборка и элементы интерфейса, расположенные ниже.
- Панели выбора устройств. Здесь вы выбираете, статистику показов на каких устройствах хотите посмотреть.
- Кнопки выбора регионов. Здесь можно отметить регионы, по которым вы хотите видеть статистику. По умолчанию она показывается по всем регионам.
- Левая — основная выборка. Это запросы, которые содержат слова, заданные нами в строке поиска.
- Правая — похожие запросы. Здесь будут фразы, близкие по смыслу к заданной нами. Они могут вообще не содержать слов из нее.
В режиме "По словам" мы видим статистику в двух панелях:
Что означают цифры напротив запросов?
Это основной параметр, который отслеживает и показывает Wordstat. Он называется "Показов в месяц", но также часто используется термин "частотность запроса". Означает количество показов по данной фразе за месяц, считая от даты обновления, которая указана справа над выборкой.
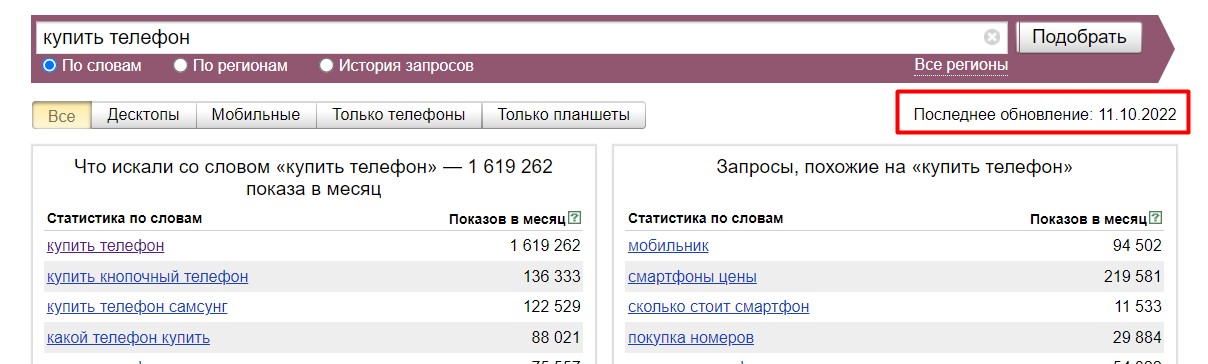
Яндекс пишет, что он показывает прогноз показов на следующий месяц, однако нужно понимать, что прогноз основан на статистике прошлого периода и не учитывает тренды или новые запросы, которые могут появиться в следующем месяце.
“Вордстат” показывает частотность заданной фразы (вверху) и отдельно по каждому ключевому слову из выборки:
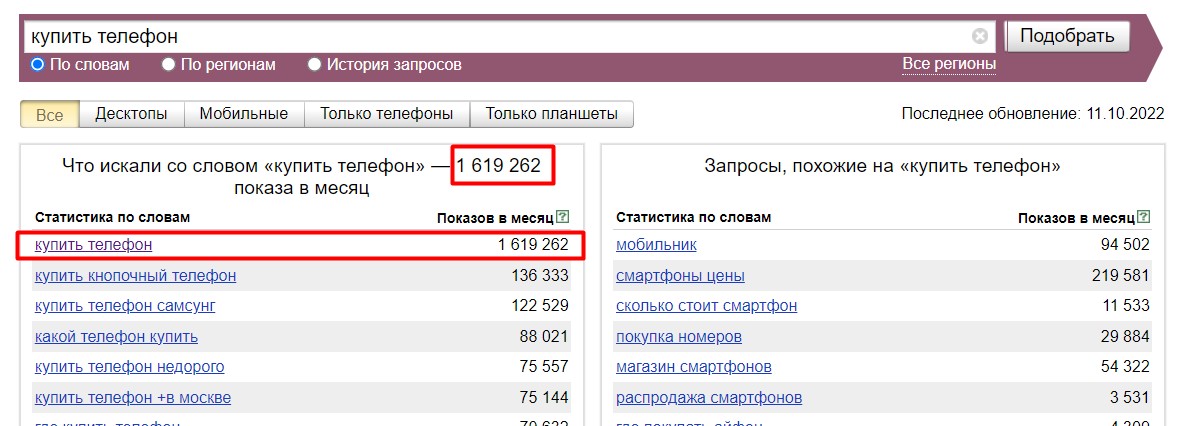
При этом нужно понимать, что в количество показов более широкого ключевого слова входит число показов производных от него ключей "с хвостами" — то есть всех запросов, которые содержат слова заданной фразы.
Например, на скрине выше:
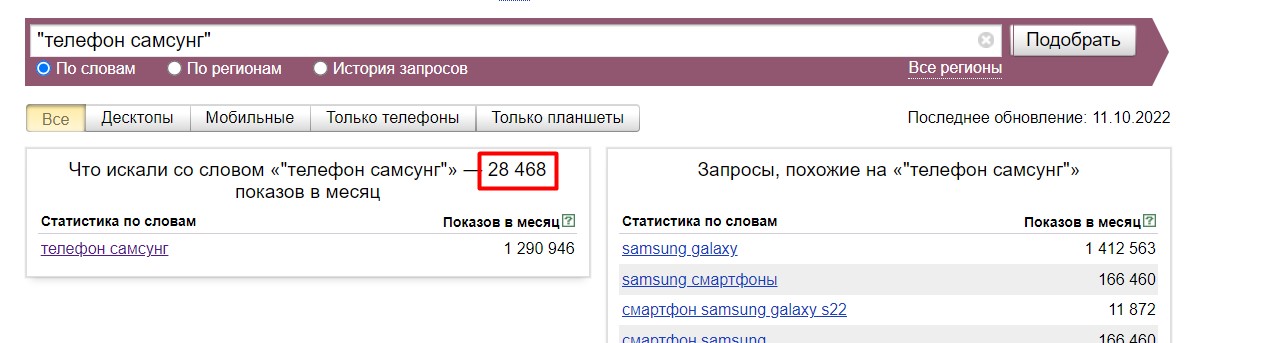
- В количество показов по фразе "купить телефон" входят показы по всем запросам из выборки, которые содержат слова "купить", "телефон" и их словоформы. Например: "купить кнопочный телефон", "купить телефон самсунг" и т. д. Чтобы узнать количество показов ТОЛЬКО по фразе "купить телефон", без хвостов, нужно использовать операторы, об этом расскажем ниже.
- В количество показов по фразе "купить кнопочный телефон" будут входить показы по всем запросам, которые содержат слова "купить", "кнопочный", "телефон" и их словоформы. Например: "кнопочный телефон самсунг купить", "купить телефон кнопочный бу" и другие.
Каждая фраза в выборке кликабельна, и по щелчку мышкой вы можете перейти на страницу с ее статистикой.
Какие ключевые слова “Вордстат” включает и не включает в выборку?
Мы уже сказали, что будут выбраны все запросы, в которые входят все слова из заданной ключевой фразы и их словоформы. Давайте разберем подробнее, какие слова “Вордстат” может включить в параметры поиска и что он считает словоформами.
В выбранной статистике мы увидим фразы, в которые будут входить:
- Существительные из заданного запроса в других падежах и другом числе (телефоны, телефона, телефоном).
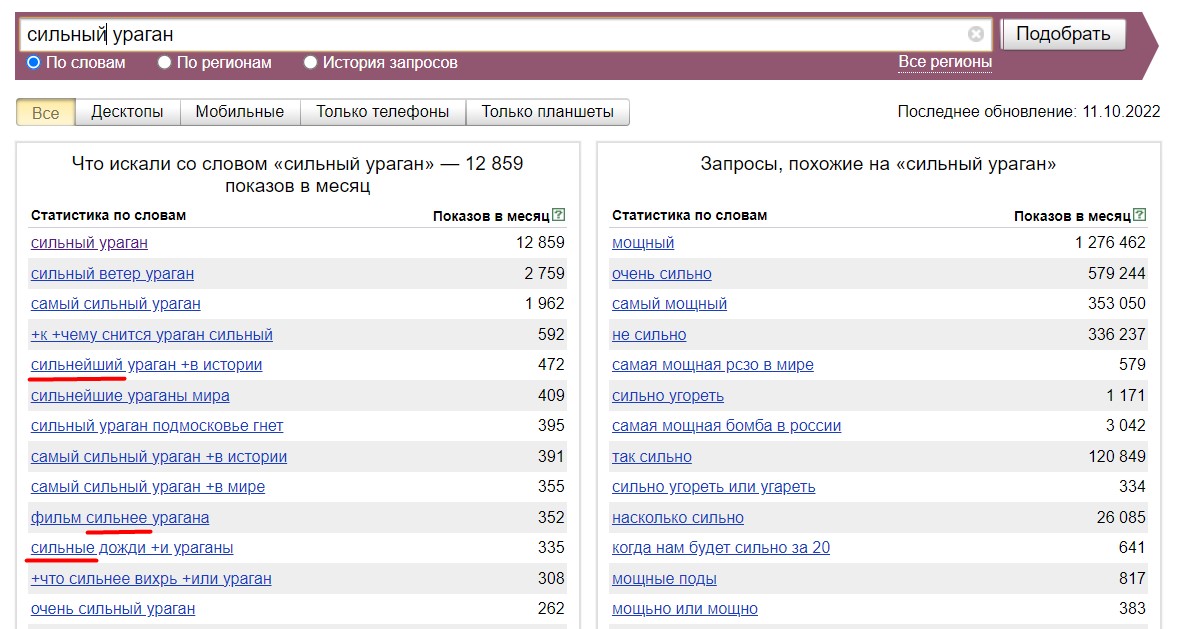
- Сравнительные формы прилагательных, а также их склонения по падежам и числам. Например, задав в Вордстате "сильный ураган" мы получим вот такую картину:
- Глаголы в различных формах, в том числе в форме причастий и деепричастий:
- Варианты написания с "е" и "ё". Например, задав слово с "ё", мы получаем:
- Различные предлоги и служебные слова, в том числе вместо тех, которые вы включили в запрос. Также будут показаны ключевые слова вообще без упомянутых вами предлогов, частиц и т. д.:
- Ну и, конечно же, различные "хвосты" — слова, которых не было в вашей базовой фразе.
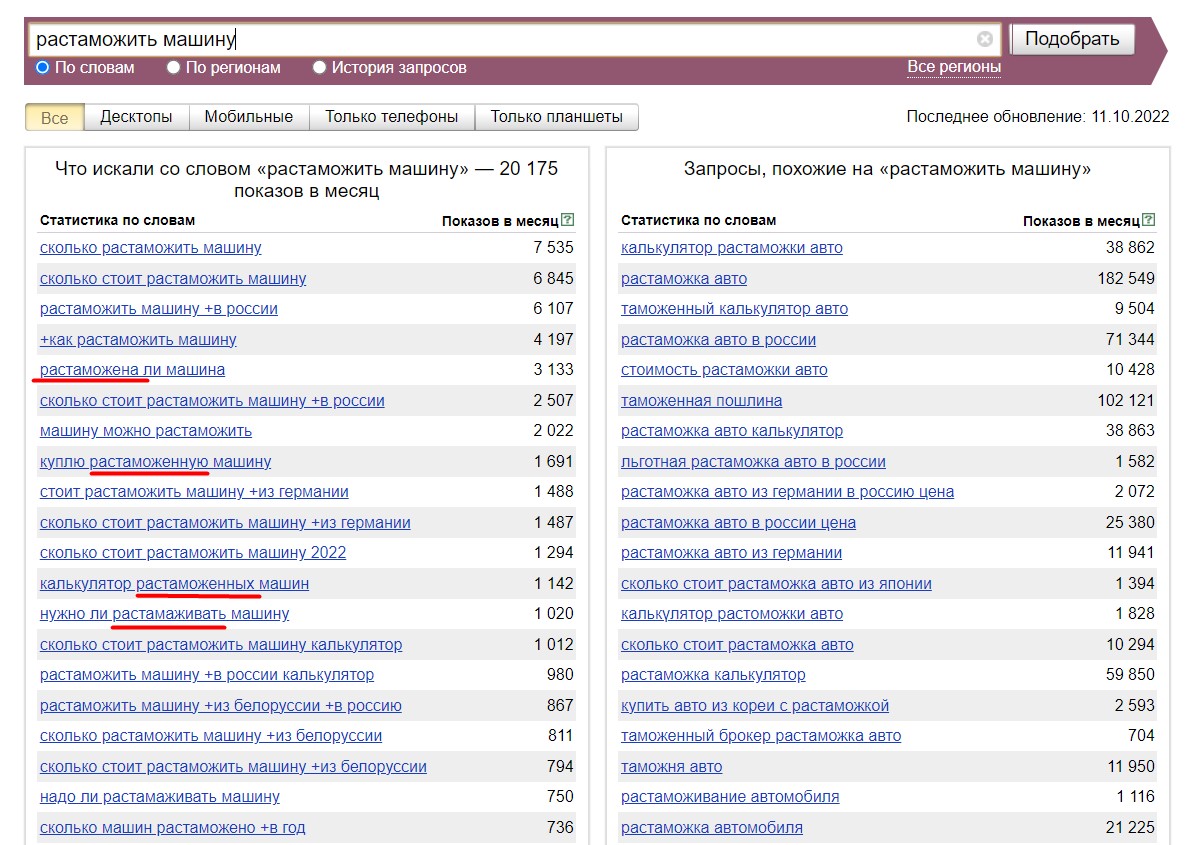
Яндекс не считает словоформами и не включает в выборку запросы со следующими словами:
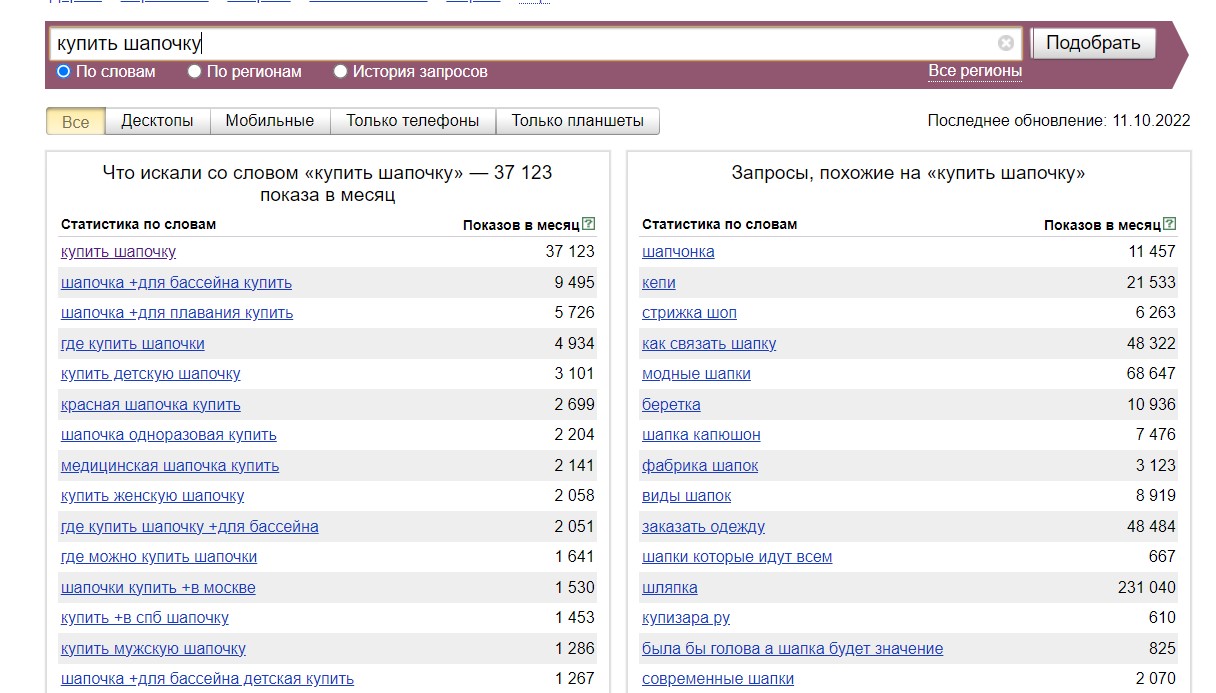
- Уменьшительно-ласкательные формы слов из базовой фразы и наоборот. Например, по фразе "купить шапку" мы не увидим ключевых слов со словом "шапочка". А по запросу "купить шапочку" мы не увидим словосочетаний со словом "шапка":
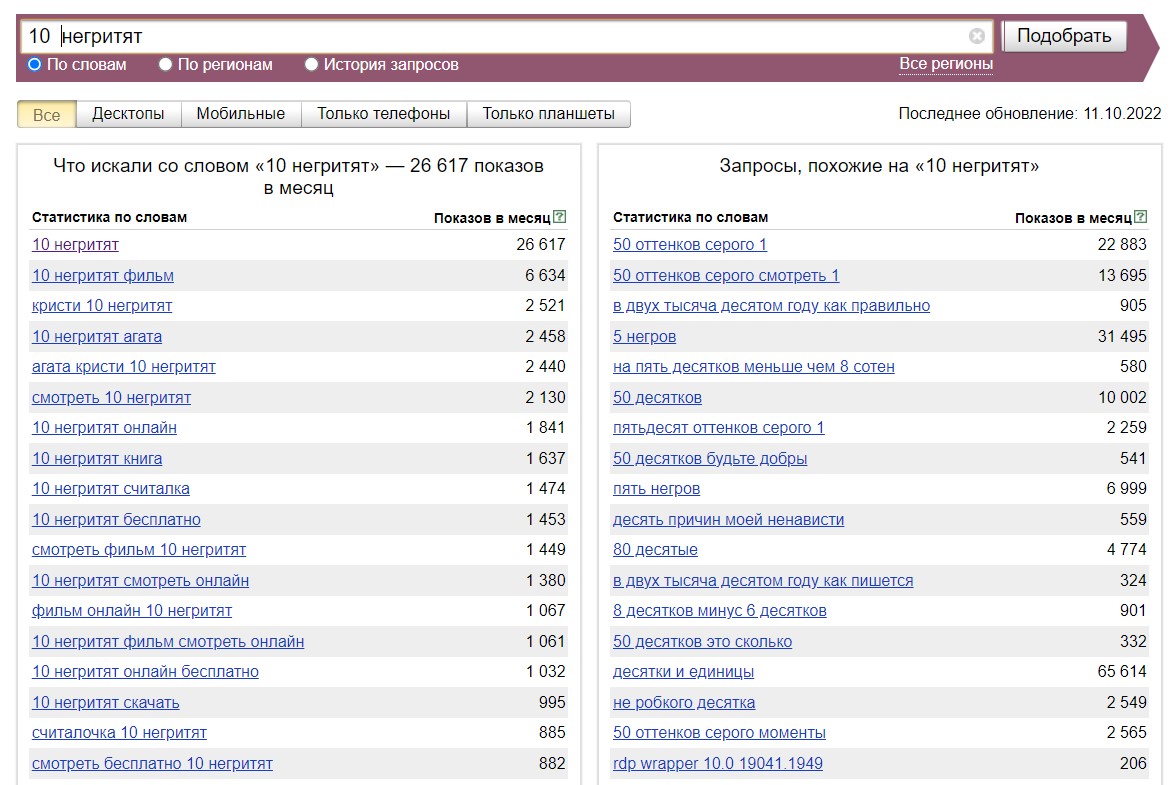
- Числительные в другом варианте написания (цифрами, словом). В примере ниже все фразы выборки — только с числительным, написанным цифрами:
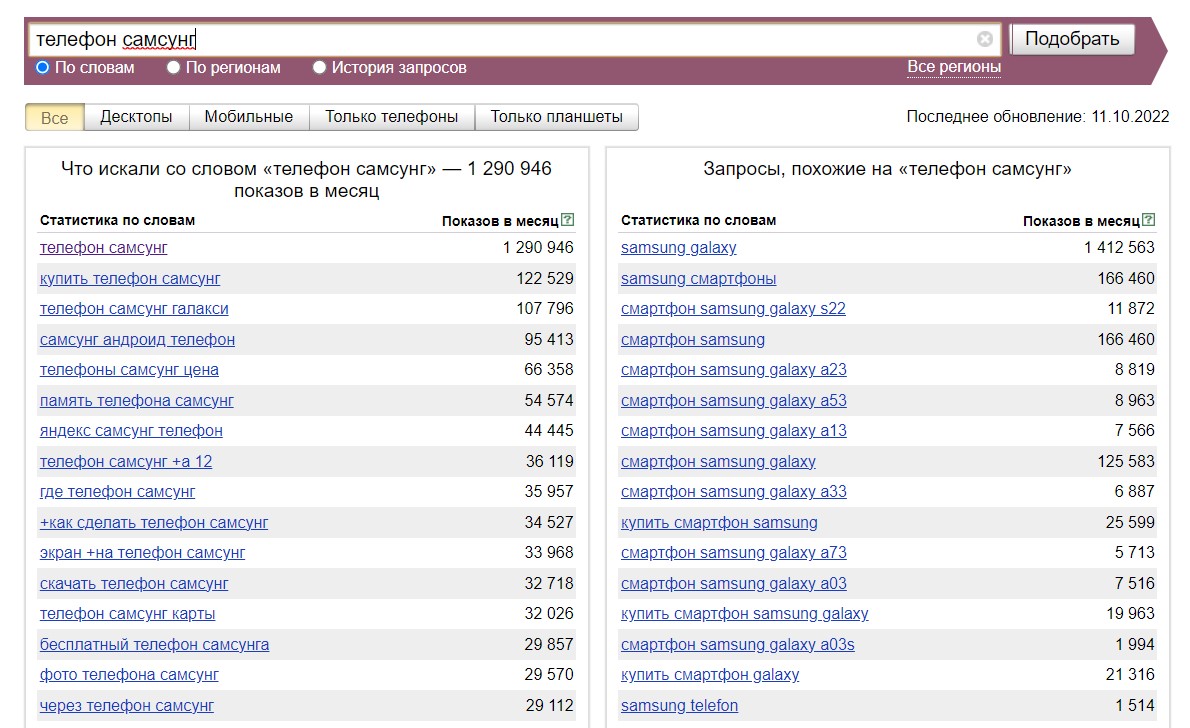
- Варианты слов в транслитерации. Например, словоформой слова "самсунг" не будет считаться "samsung":
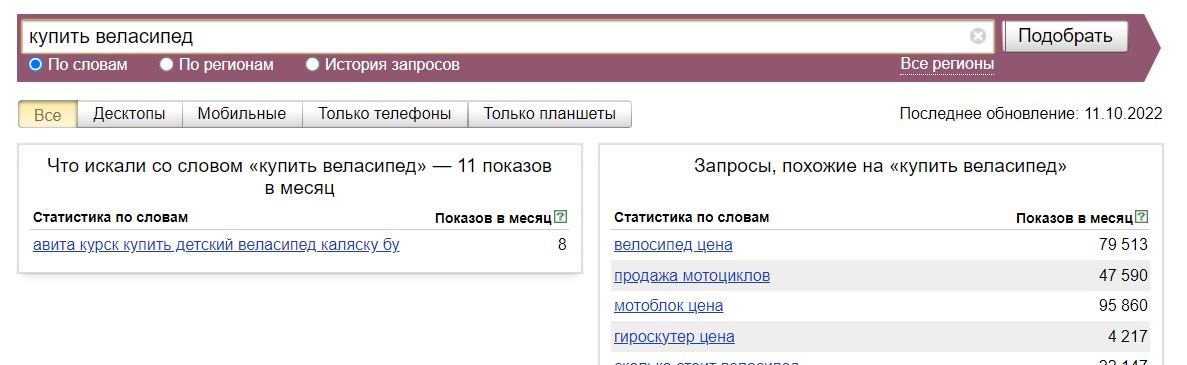
- Слова из заданной фразы с опечатками. Например, по фразе "купить велАсипед" вам покажут только запросы, которые вводились с опечаткой:
- Слова с приставками. Это правило вполне понятно, ведь, к примеру, "корм для рыб" и "прикорм для рыб" — это совершенно разные по интенту запросы, они означают разные товары.
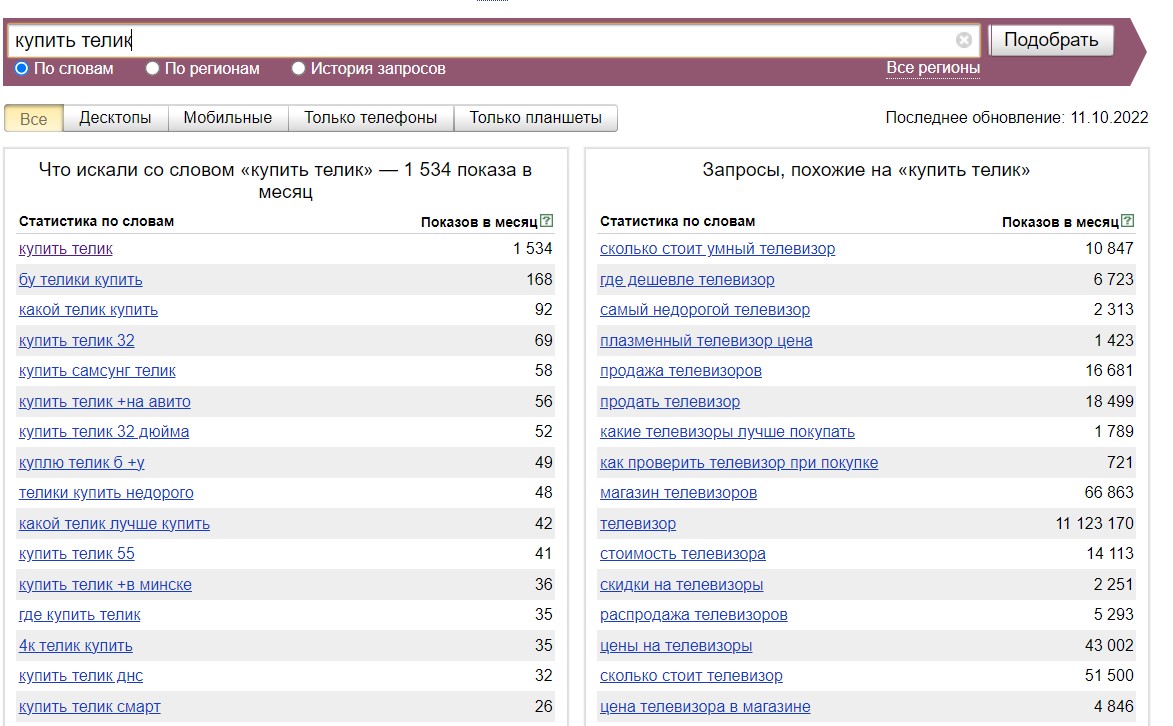
- Разговорные, жаргонные формы слов. Например, в выборку по фразе "купить телик" не будут входить ключевики со словом "телевизор":
Хотя в самом поиске “Яндекс” прекрасно понимает, что это опечатка, моментально исправляет ее и выдает правильные результаты. Вероятно, именно из-за исправления "на лету", слово с опечаткой чаще всего не попадает в статистику.
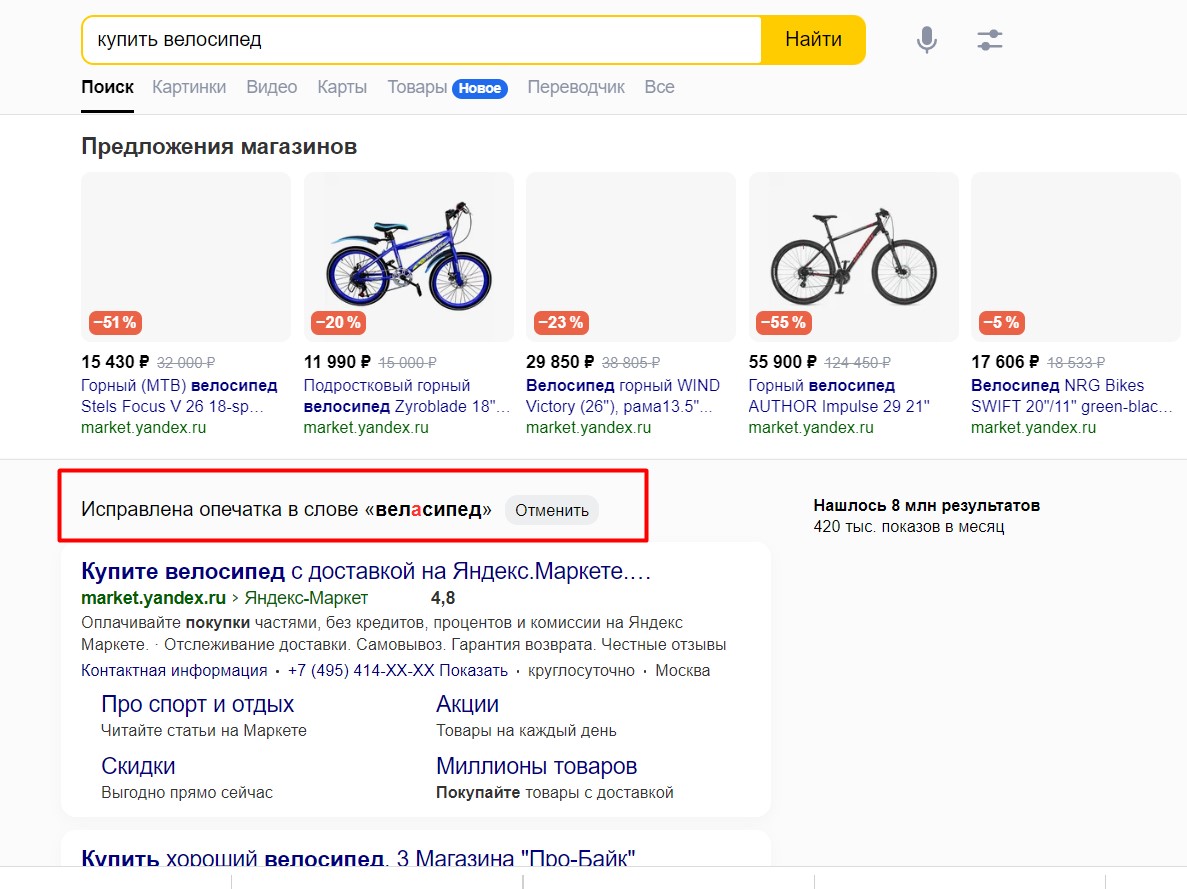
Но такие слова, конечно, могут включаться в запросы в качестве "хвостов". Например, "купить телефон самсунг samsung" будет показан в статистике по фразе "купить телефон самсунг".
Как уточнить базовую фразу с помощью операторов
Часто простой запрос дает не совсем релевантный результат. В выборке может быть много ненужных нам словосочетаний, не с теми предлогами, без нужного нам предлога, "с хвостами" — тогда как нам нужна статистика без них, и так далее.
Чтобы получить более подходящий результат, можно уточнить нашу фразу с помощью операторов.
Обратите внимание, когда вы используете операторы, частотность уточненной фразы нужно смотреть вверху. В самой выборке по ней будет по-прежнему общая частотность:
Как сделать, чтобы слово обязательно входило во все фразы статистики
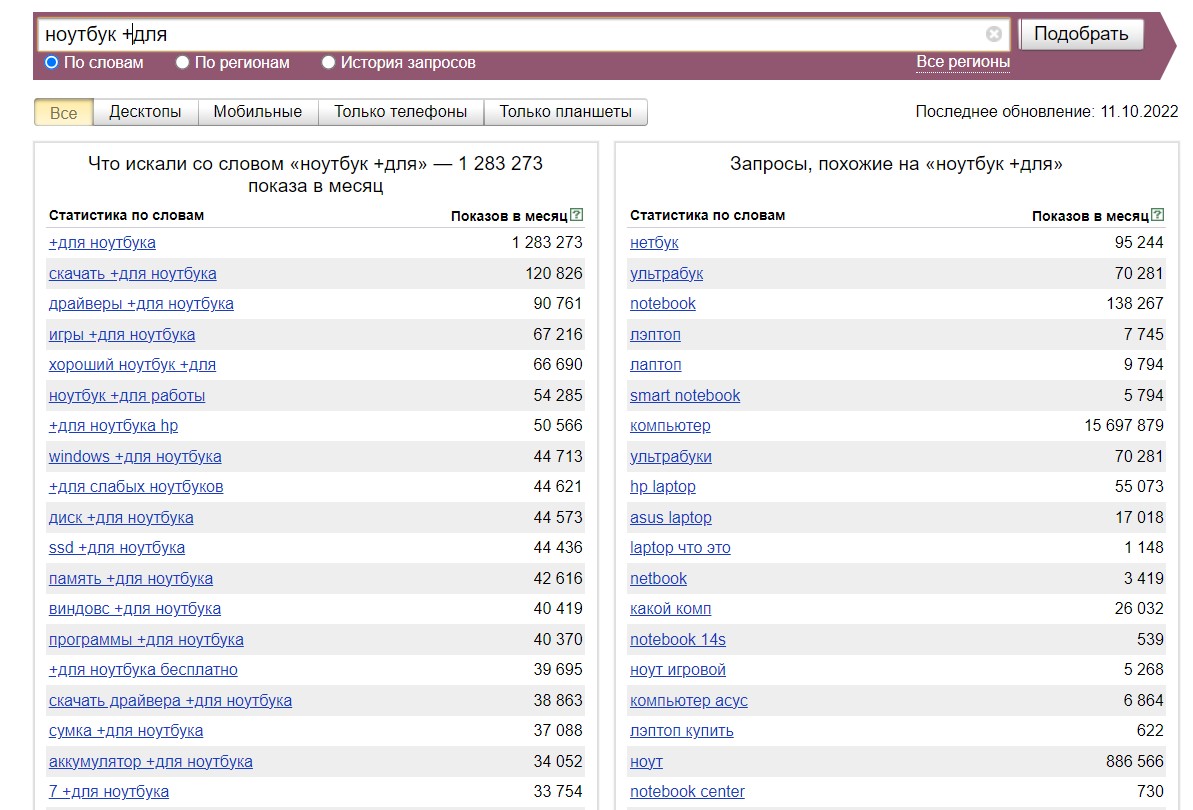
Используем оператор "+" (плюс). Предлоги, частицы, местоимения и другие служебные слова “Яндекс” не считает обязательными при выборе статистики. Чтобы они обязательно содержались во фразах выборки, поставьте перед ними +.
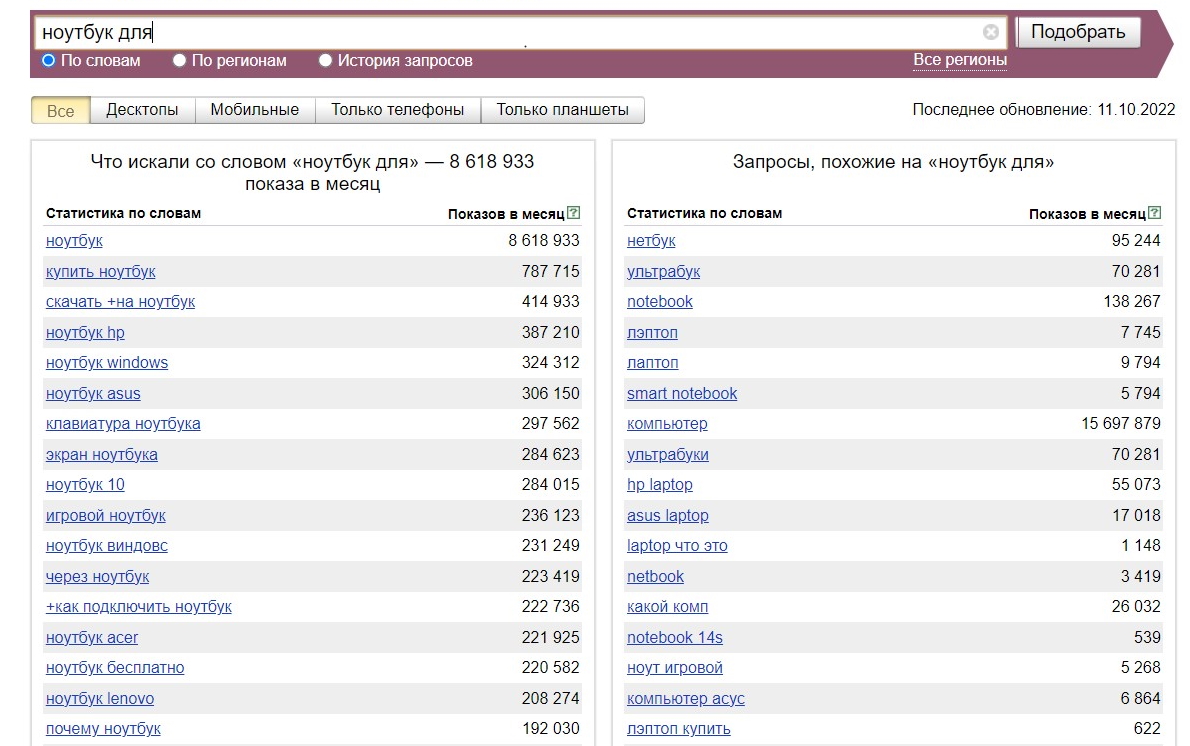
Например, вы хотите выбрать ключевые слова, в которых люди определяют назначение товара — для чего они его покупают. Без оператора вы получите массу ненужных запросов. “Вордстат” просто проигнорирует "для":
С оператором "+" все запросы будут со словом "для" (выборка все еще не совсем релевантна нашей задаче и требует дополнительного уточнения, но об этом чуть ниже):
Как исключить запросы с определенными словами
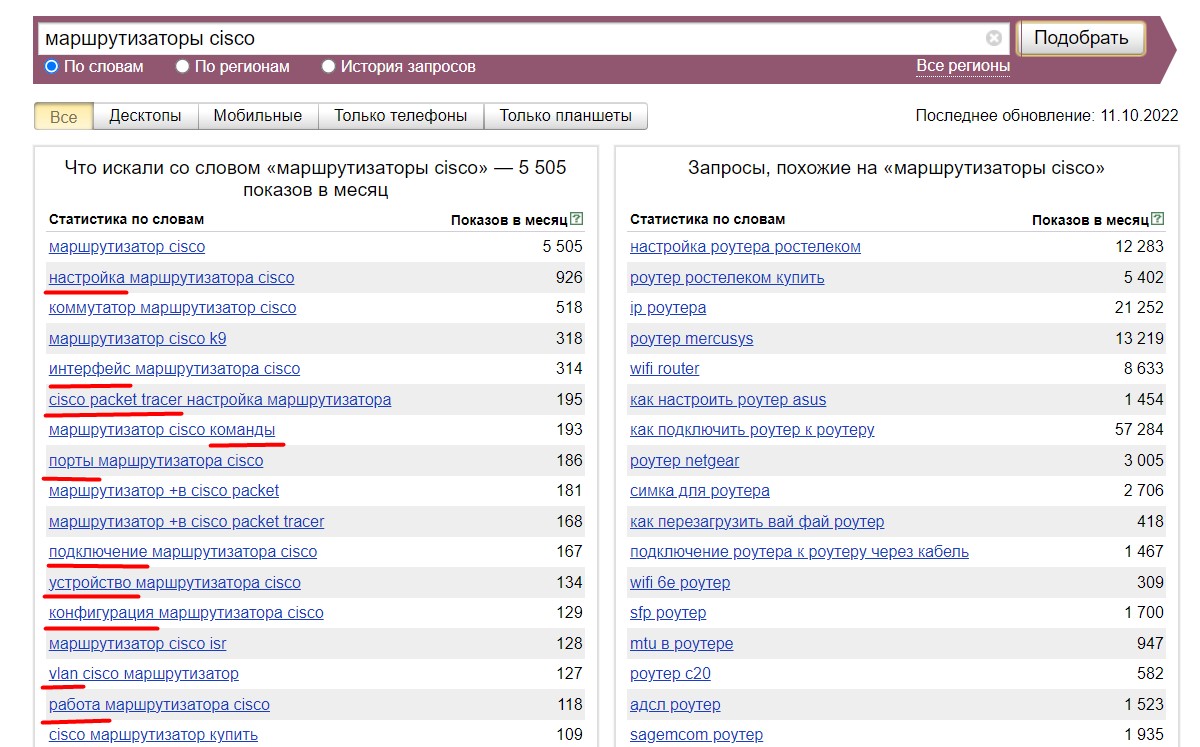
Используем оператор "-" (минус). Чтобы исключить сбор словосочетаний, которые вам не нужны, можно задать в базовой фразе минус-слова.
Например, вы продаете маршрутизаторы Cisco и хотите собрать коммерческие ключи. Статистика по ключевому слову "маршрутизатор cisco" будет перенасыщена информационными запросами от сисадминов, которые настраивают это оборудование:
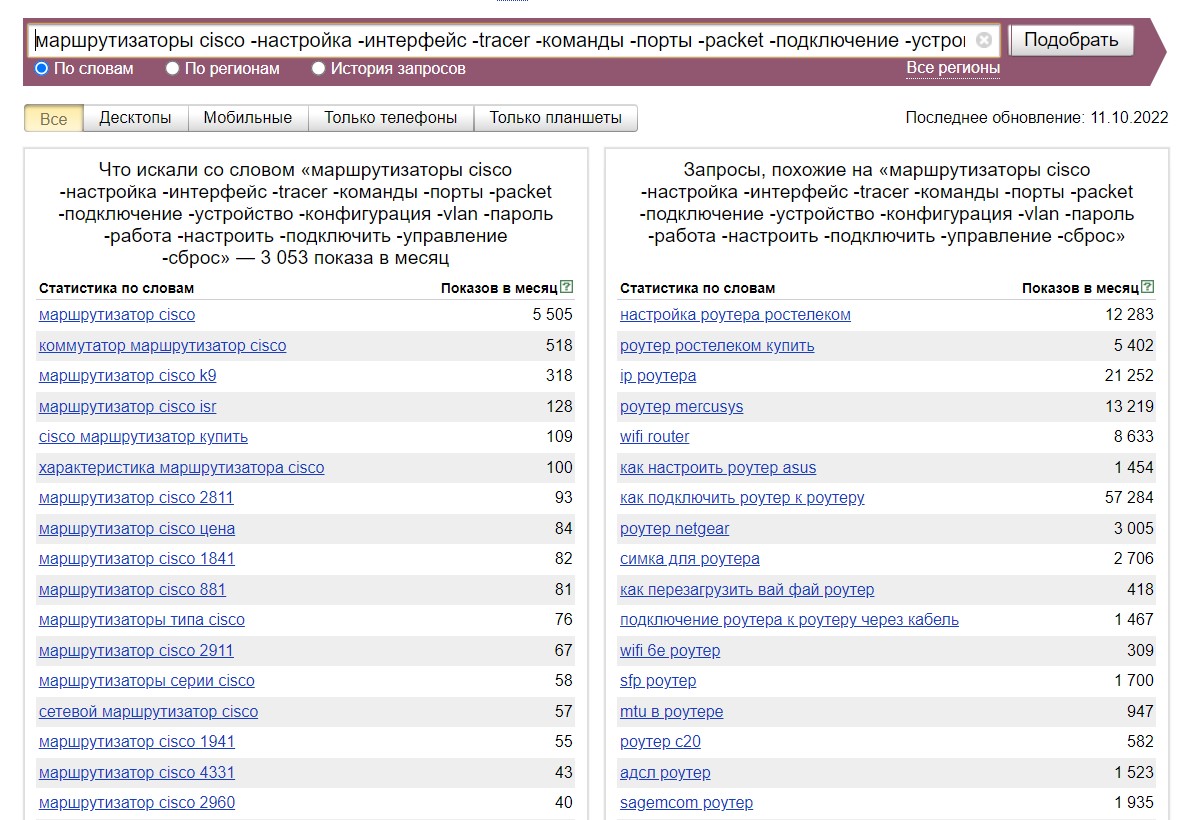
Задайте в строке поиска исключаемые слова с минусом впереди, и результат будет уже другой:
Как сделать, чтобы слово было строго в заданной словоформе
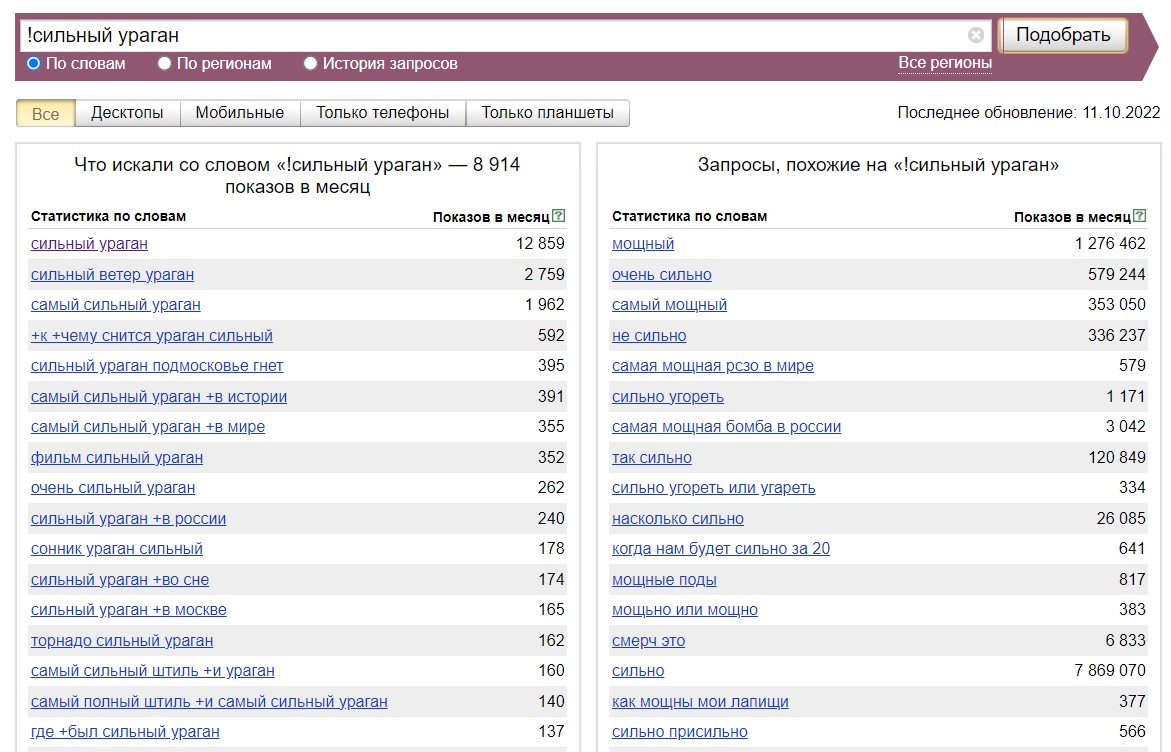
Используем оператор "!" (восклицательный знак). Если вам нужно выбрать фразы без словоформ, поставьте перед нужным словом восклицательный знак.
Например, вы не хотите, чтобы в статистику по ключу "сильный ураган" попали запросы со словоформами "сильнейший" или "сильнее". Пишите так:
Как выбрать ключи только с указанными словами, без "хвостов"
Используем кавычки «». Чтобы узнать частотность заданного словосочетания без хвостов, поместите ее в кавычки. Вверху будет показана частотность уточненной фразы:
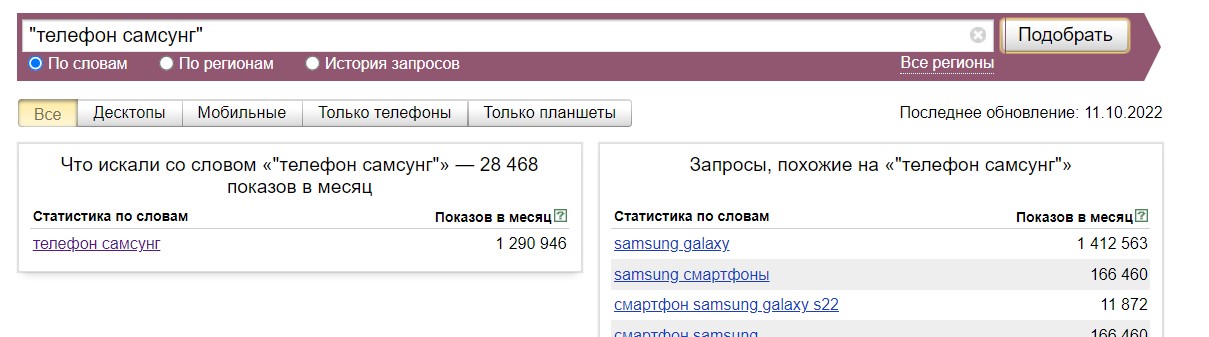
Как выбрать запросы со строго заданным порядком слов
Используем квадратные кавычки [ ]. Помните, чуть выше с помощью оператора "+" мы хотели получить выборку — для чего люди ищут ноутбуки? Она была не совсем релевантной, так как в нее попали запросы людей, которые запрашивали не ноутбук для чего-то, а что-то для ноутбука.
Проблему можно решить, задав строгий порядок слов, чтобы "для" шло после "ноутбук". Для этого помещаем фразу в квадратные кавычки. "+" перед предлогом можем не писать, поскольку в квадратных кавычках все слова по умолчанию становятся обязательными.
Получаем уже гораздо более релевантный результат:
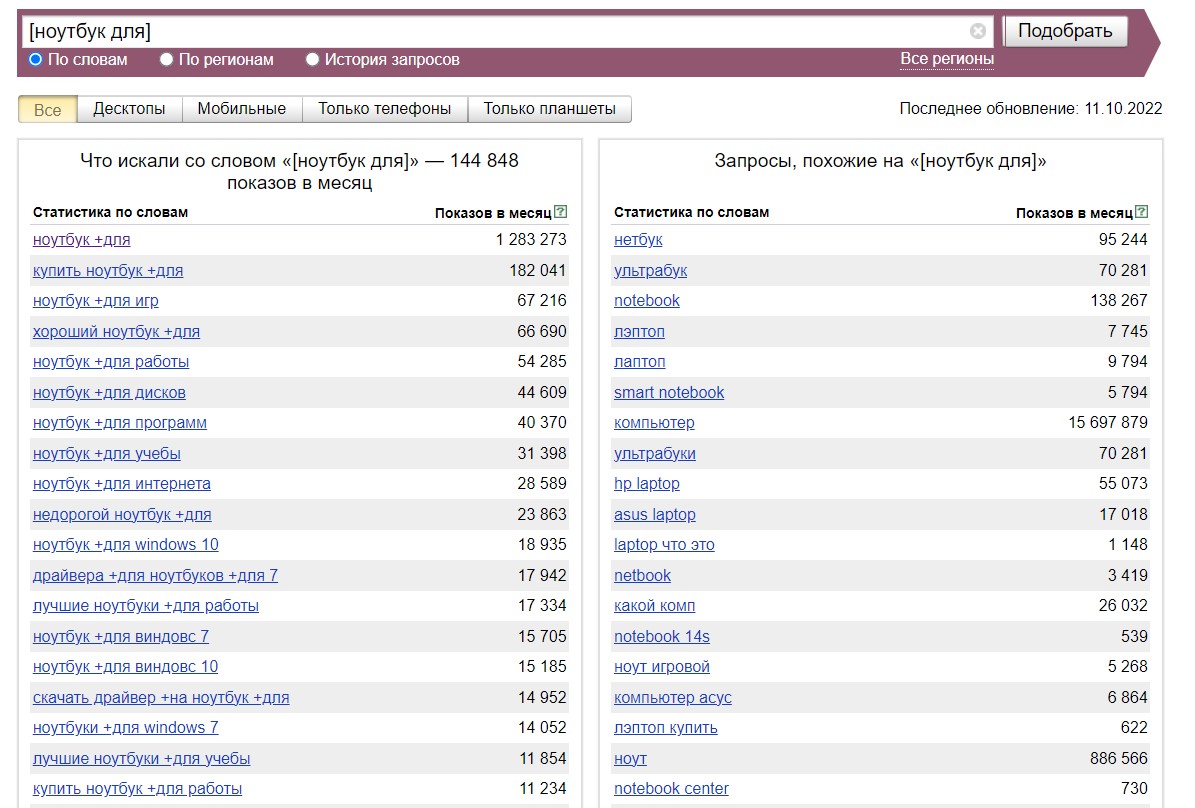
Как выбрать запросы с определенным количеством слов или обойти ограничение в 41 страницу
Используем повторение слов, заключенных в кавычки.
При работе в “Вордстате” с высокочастотной тематикой возникает две проблемы:
- Самые лучшие и перспективные запросы обычно состоят из 3-4 слов. Но базовая фраза обычно короче, поэтому в статистике будет много ключей из одного-двух слов, которые вам не нужны.
- Выборка ограничена 41 страницей. А нужные вам ключи чаще всего находятся дальше.
Чтобы получить ключи с определенным количеством слов, заключите свою базовую фразу в кавычки и повторите одно из слов столько раз, сколько нужно.
Например, вы хотите получить запросы из 4 слов по базовой фразе "купить телефон". Напишите в строке поиска:
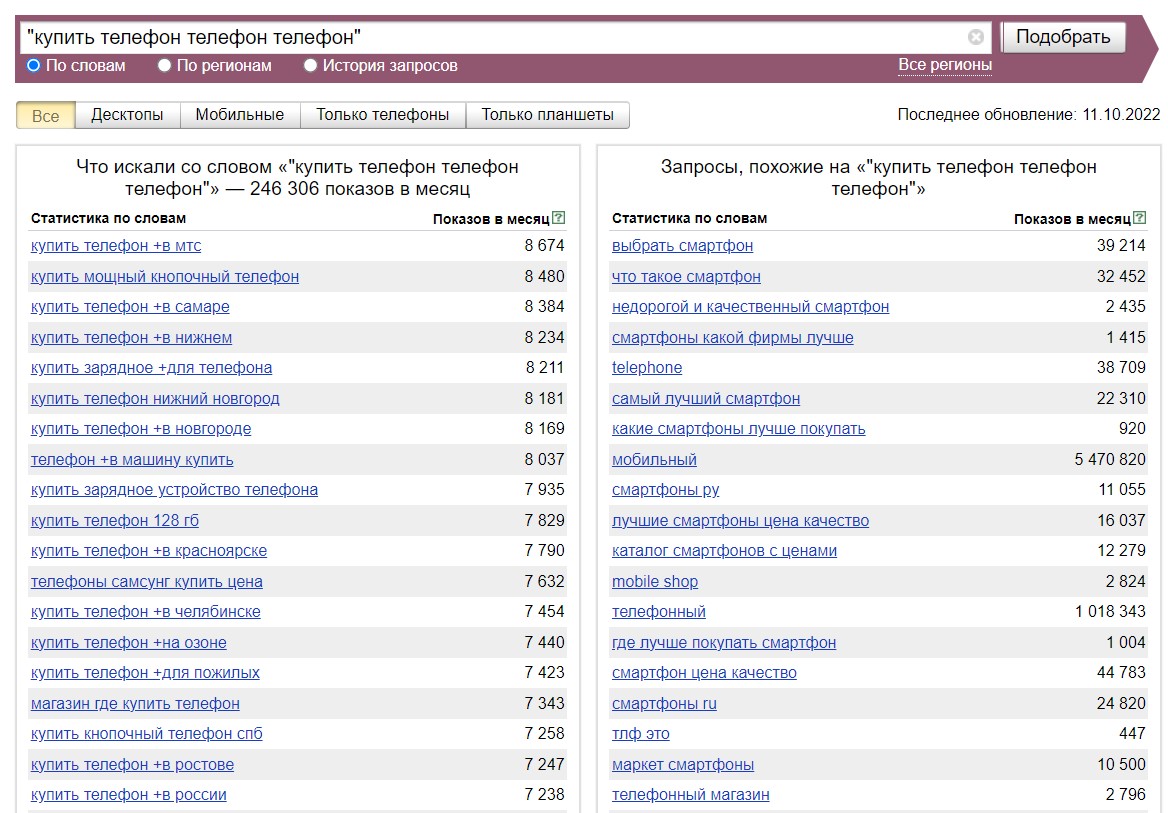
Как это работает? Кавычки дают команду вордстату собрать ключевики только с тем количеством слов, которые в них заключены. При этом в них должны содержаться слова из базовой фразы, а их там только 2, остальные повторяются. Вот “Вордстат” и ищет результаты из 4 слов с вхождением "купить" и "телефон".
Как выбрать запросы с синонимами (оператор "или")
Используем круглые скобки и вертикальную черту ( … | … ). Чтобы собрать как можно больше ключевых слов за одну итерацию, можно включить в базовую фразу синонимы, или варианты, которые “Вордстат” не считает словоформами. Для этого ставим между синонимами вертикальную черту “|” и заключаем всю конструкцию в круглые скобки.
Например, вы хотите собрать за один раз статистику по ключам "телефоны самсунг" и "телефоны samsung". Напишите в поисковой строке "телефоны (самсунг|samsung)". В выборке будут ключевые слова с обоими вариантами написания бренда:

Примеры сложных запросов с использованием операторов
Операторы можно комбинировать и получать в результате сложные конструкции базовой фразы. Это позволяет сузить критерии выбора статистики, избавить себя от отсеивания мусорных ключевиков в выборке и т. п.
Пример № 1. Проверяем частотность точного запроса
Чтобы посмотреть частотность запроса именно в той словоформе, которую мы задали, точно с тем порядком слов и без хвостов, комбинируем квадратные скобки, кавычки и восклицательный знак:
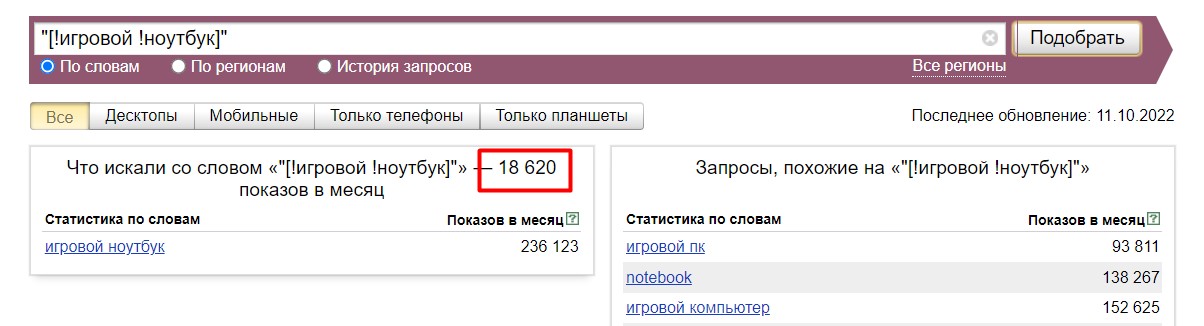
Пример № 2. Собираем максимум коммерческих запросов для “Директа”
Комбинируем операторы "или" и минус-слова. К примеру, мы хотим рекламировать моющие пылесосы Xiaomi. Вы знаете, что покупатели называют его "моющий" или "с влажной уборкой", а бренд Xiaomi транслитерируют по разному. Плюс хотите исключить информационные ключевики, например "как подключить", "пылесос не работает" и другие. Можно задать в “Вордстате” такой запрос:
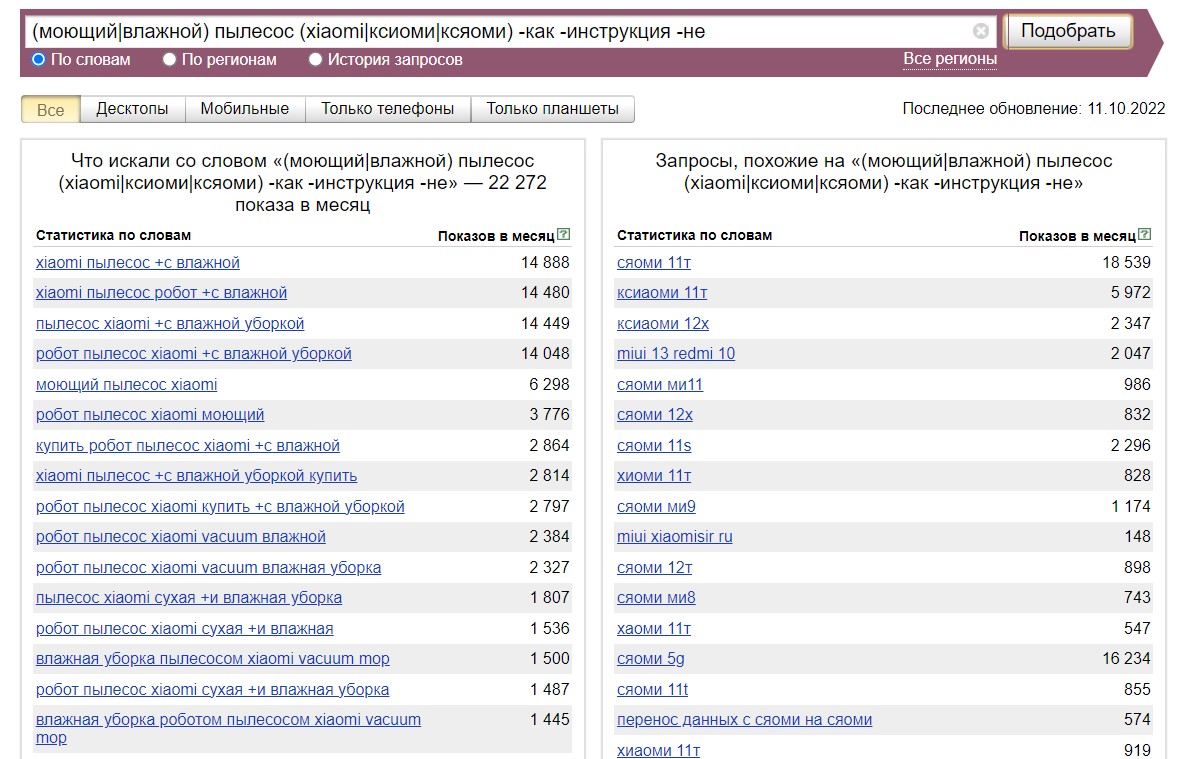
На скрине не поместилось, но в выборке также есть запросы с "ксиоми" и "ксяоми".
Пример № 3. Выбираем менее частотные словоформы
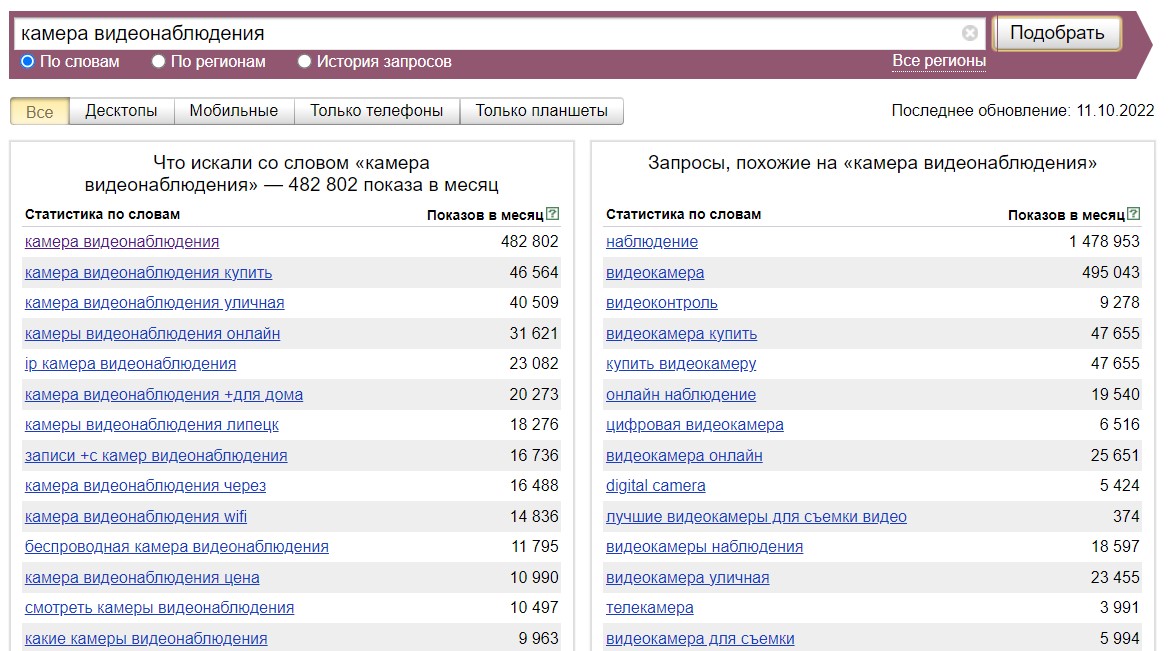
Допустим, у нас есть высокочастотное ключевое слово, нам нужно найти его словоформу, вторую после популярности после основной, чтобы продвигать ее, а не высококонкурентную первую. Чтобы сделать это, мы исключаем точное написание запроса и получаем нужный нам ключевик.
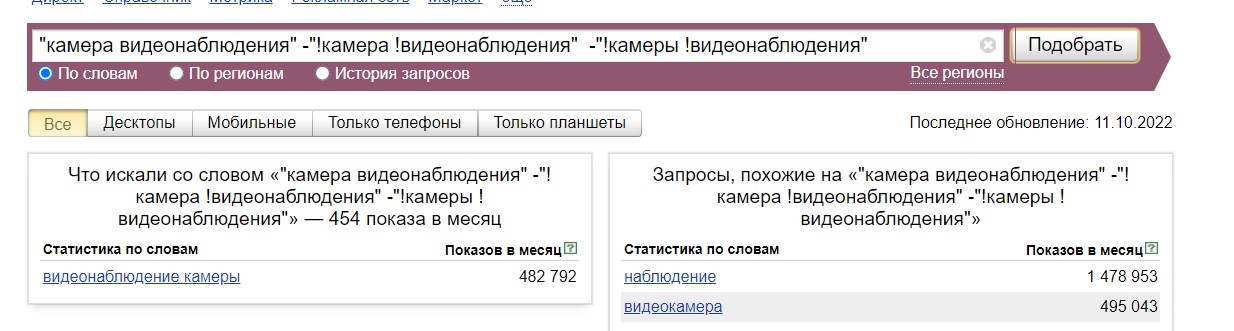
Например, если задать фразу "камера видеонаблюдения" без кавычек, то мы получим обширную статистику, в которой очень сложно найти желаемое:
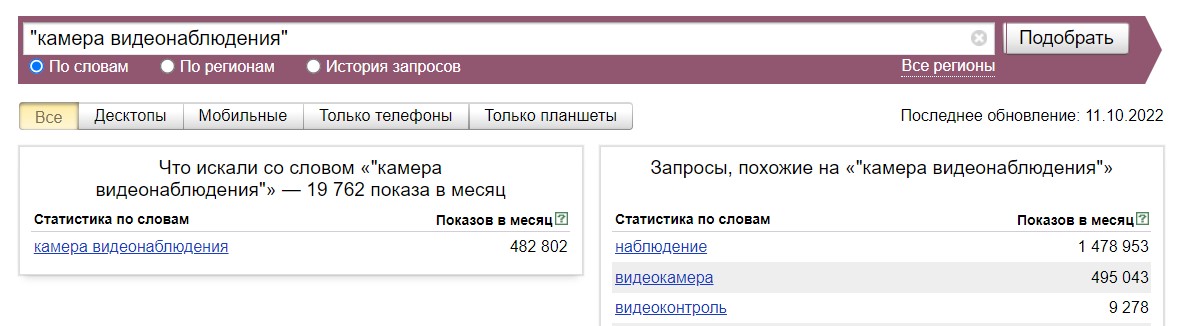
Если ключевое слово задать в кавычках, то мы получим вот такой результат. Показана только та словоформа, которую мы задали:
Но если задать "камера видеонаблюдения" в кавычках, и тут же исключить точную форму этого запроса -"!камера !видеонаблюдения", то “Вордстат” выдаст вторую по популярности словоформу:
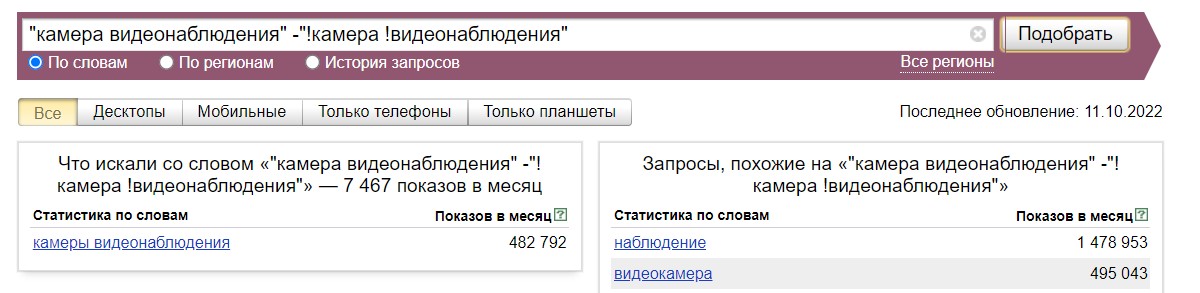
А если исключить и ее, то третью:
Просмотр статистики в режиме "По регионам"
Чтобы посмотреть общую статистику по одному или нескольким регионам сразу, вы выставляете нужный регион здесь:

Но что, если вы хотите сравнить популярность ключевого слова в нескольких регионах? Несколько раз менять настройку гео и просматривать данные отдельно — неудобно.
В этом случае воспользуйтесь режимом "По регионам". В нем частотность заданного вами запроса будет проставлена по каждому региону:
Можно смотреть на вкладке "Все", а можно на отдельных вкладках "Регионы" и "Города". Также работает просмотр частотности по отдельным устройствам.
По умолчанию данные отсортированы по убыванию частотности, но можно кликнуть на заголовок столбца "Региональная популярность" и отсортировать по нему.
Региональная популярность
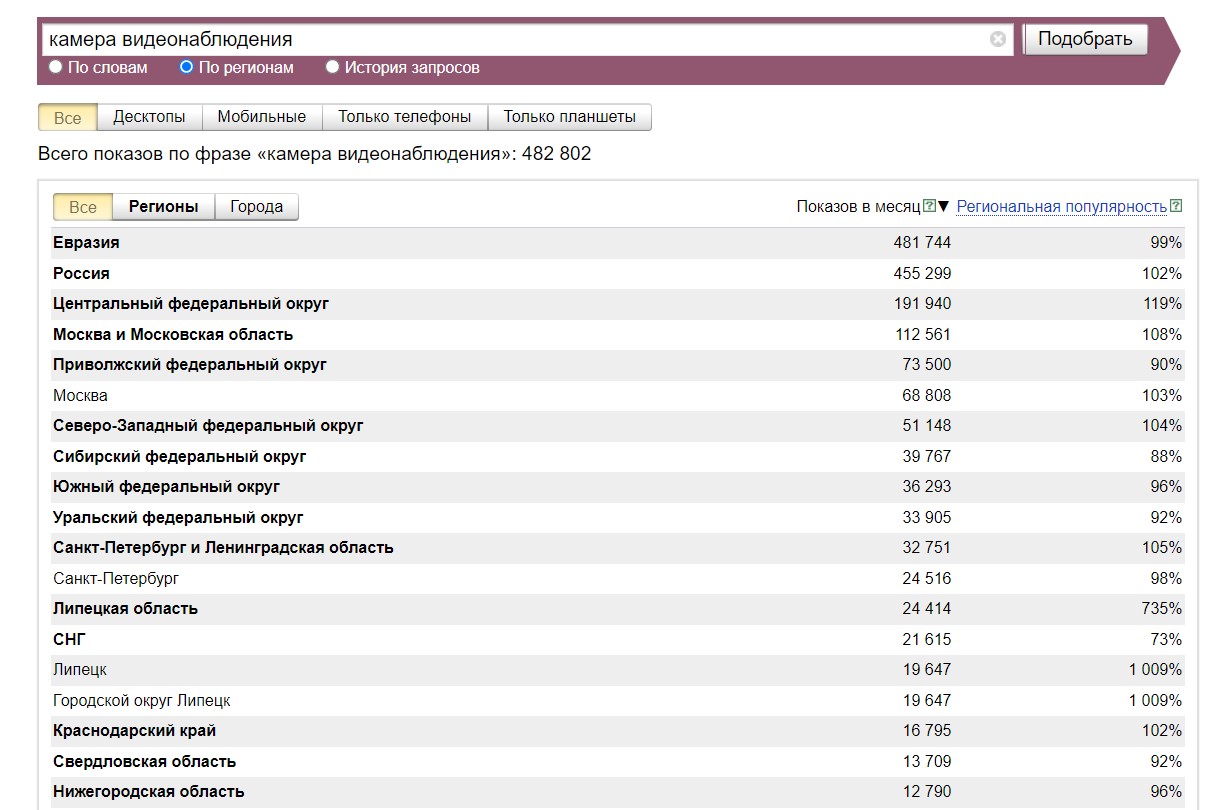
Помимо обычной частотности (показов в месяц), здесь есть еще параметр "Региональная популярность" (крайняя правая колонка). Он показывает увеличенный или уменьшенный интерес к запросу в определенном регионе.
Расчет показателя покажем на условном примере.
Допустим, есть некий запрос с количеством показов по всем регионам 10 000. В Москве количество показов составляет 8 000, итого доля его показов в Москве — 80 %. Это популярность конкретно этого ключевого слова в Москве.
При этом в целом по всем поисковым фразам Москва занимает 70 % всех показов во всех регионах. Это общая региональная популярность запросов москвичей.
Чтобы получить региональную популярность ключевика, мы делим первое значение на второе, то есть 80 % на 70 %. И получаем коэффициент 1,14, или, если в процентах, 114 %.
Этот параметр помогает понять, действительно ли большое число показов в определенном регионе означает повышенный интерес к нему или это обусловлено в целом большей плотностью статистики в этом регионе.
- Если региональная популярность равна 100 % — популярность ключевого слова в этом регионе на обычном, среднем уровне.
- Выше 100 % — фраза в этом регионе более популярна, чем в других.
- Ниже 100 % — менее популярна.
Например, мы видим, что в СПб показов по фразе "камера видеонаблюдения" почти на 5 тысяч больше, чем в Липецке:

Однако региональная популярность фразы "камера видеонаблюдения" в Липецке почти в 10 раз выше, чем в СПб, и составляет 1009 %, тогда как в СПб — 98 %. Это означает, что в Липецке действительно наблюдается бум на запросы по видеокамерам, а вот в СПб — никакого ажиотажа нет, даже чуть прохладнее, чем в целом по другим регионам.
Просмотр статистики в режиме "История запросов"
В этом режиме вы можете наблюдать, как менялась популярность заданной фразы за 2 последних года. Учтите, что уточняющие операторы здесь не работают.
С помощью инструмента можно выявить:
- Стабильный рост или, наоборот, падение, популярности запроса. Отсюда можно делать выводы и корректировать маркетинговую политику, убирать/добавлять товары в ассортимент и т. д.
- Сезонность спроса — есть или нет. Помогает корректировать стратегию SEO-продвижения, планировать рекламные мероприятия. Если каждый год вы видите падения или взлеты частотности фразы примерно в одно и то же время, можно говорить о сезонности.
Интерфейс “Вордстата” в этом режиме содержит 3 новых элемента:
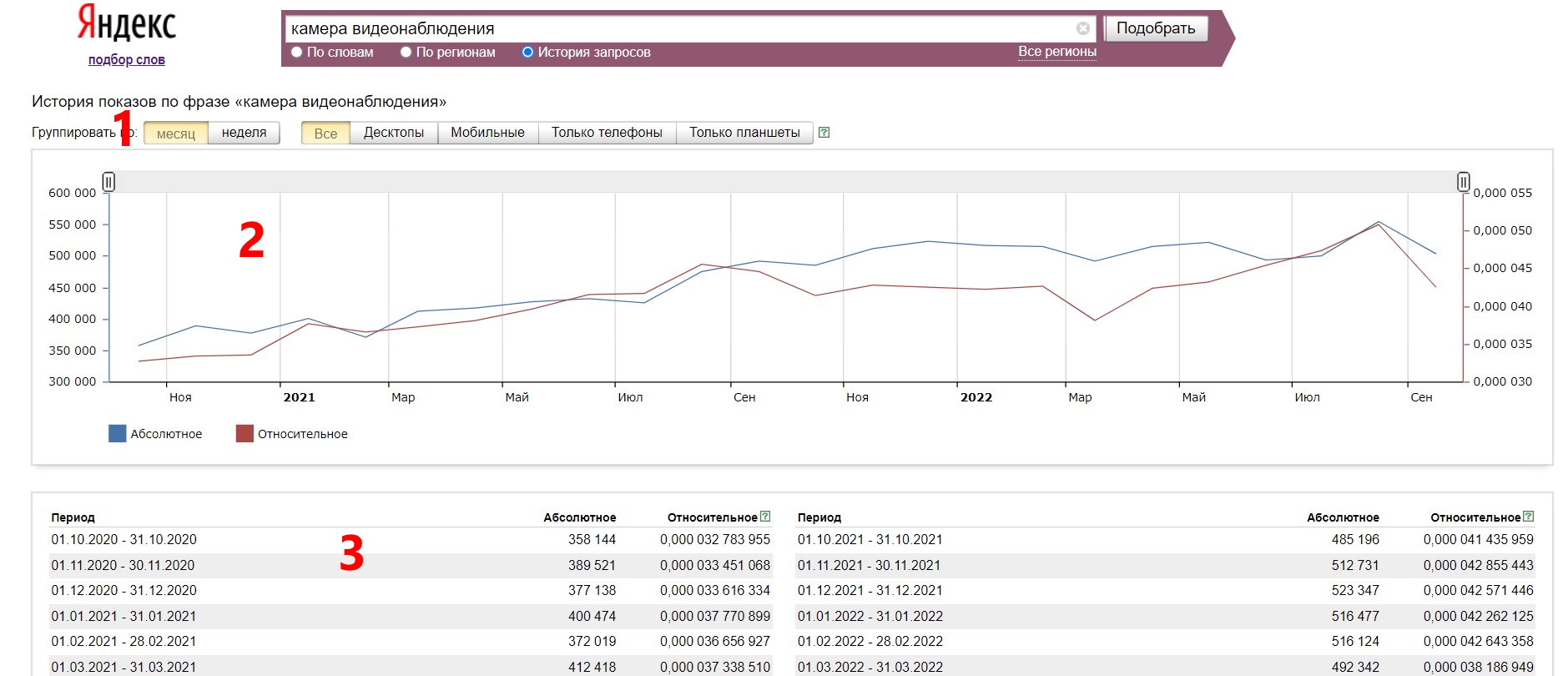
- Управление периодами группировки. Можно посмотреть частотность ключевика в разрезе месяцев или недель.
- Наглядный график популярности ключевого слова, в абсолютном и относительном значениях.
- Данные о популярности в разрезе периодов — месяцев или недель.
В этом отчете используется два параметра: абсолютное число показов в месяц и относительная популярность фразы.
Абсолютное число — это уже знакомая нам частотность, число показов ключевика в тот месяц, о котором идет речь в отчете.
Относительная популярность — это популярность данного ключевого слова в этот период относительно всех остальных запросов данного периода.
В норме они должны меняться примерно одинаково, на графике их линии должны идти практически рядом. Если есть большие расхождения, то, скорее всего, имели место искусственные накрутки спроса.
Полезные программные расширения
Есть несколько расширений для Google Chrome (можно найти и в других браузерах), которые позволяют сделать работу с “Вордстатом” более удобной — Yandex Wordstat Helper, Yandex Wordstat Assistant и другие.
Принцип работы у них примерно одинаковый. На странице статистики появляются дополнительный виджет и кнопки "+" и "-".
Интерфейс “Яндекс Вордстат Хелпер”:
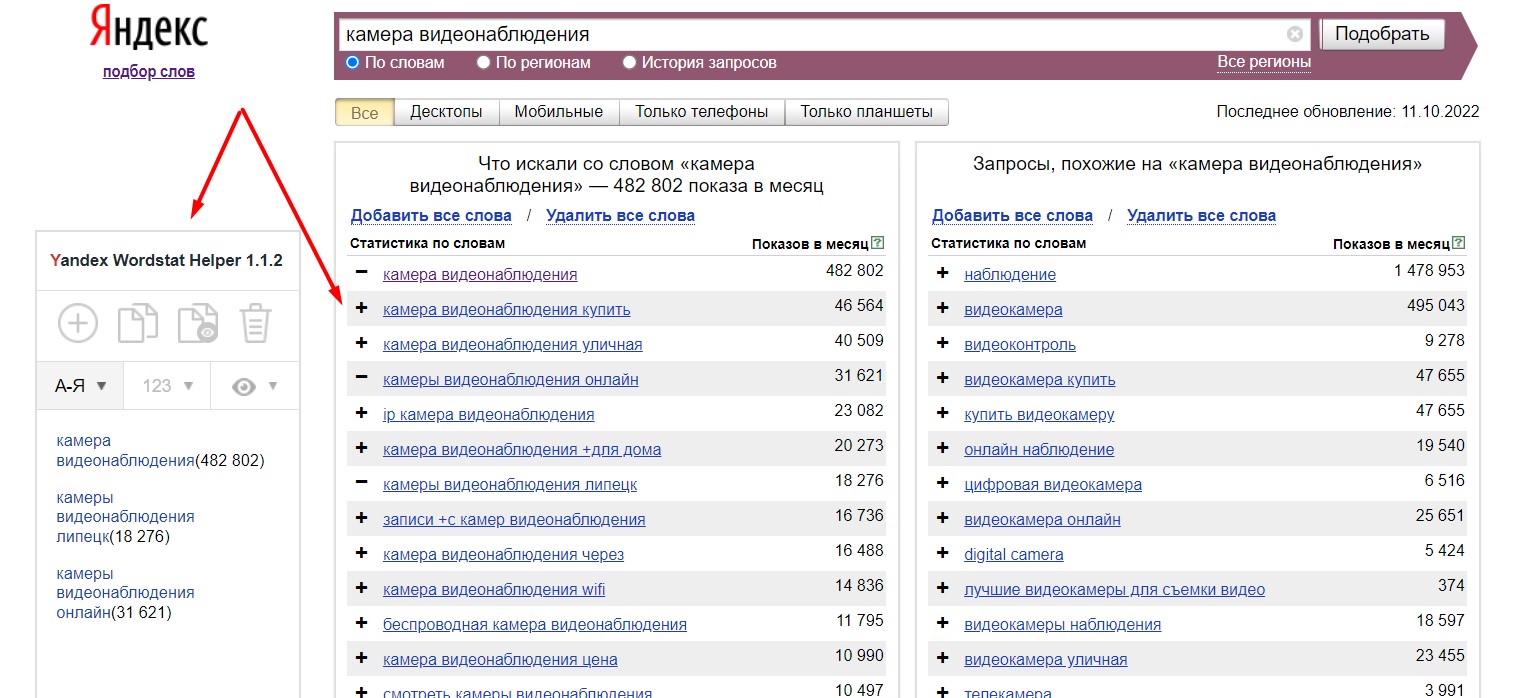
Кнопками можно добавлять выбранные фразы в список в виджете и удалять их из него. В списке запросы можно сортировать, копировать с частотностью или без для вставки в текстовый редактор и т. д.
Таким образом, решается главная проблема — массовая выгрузка выбранных вами ключевиков из веб-интерфейса Wordstat.
Заключение
“Яндекс Вордстат” — бесплатный и простой инструмент. Он не подойдет, например, для сбора семантического ядра большого сайта, в этом случае лучше парсить статистику с помощью сторонних приложений, через API. Однако для более простых задач его хватает с головой. Особенно если использовать возможности уточнения запросов, о которых далеко не все знают.
А с помощью специальных расширений можно сделать работу в нем более удобной, несмотря на несколько устаревший интерфейс.